 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Auto-Optimization in Unknown Environments via Structure-Exploiting Dual Control for Exploration and Exploitation
May 21, 2026This paper develops a fast numerical dual control for exploration and exploitation (DCEE) method to address auto-optimization problems in unknown environments. In auto-optimization problems, the optimal operating condition is unknown a priori and may vary with the environment. As in classical dual control techniques, computational burden remains a major concern in DCEE for active learning. Existing DCEE methods provide a principled exploration-exploitation objective, but mainly realized through standard optimization packages or explicit gradient-type update laws, where the numerical structure of the DCEE has not been fully exploited. This paper shows that the reward function in DCEE has an inherent convex-over-nonlinear structure, where the exploitation and exploration terms form a unified nonlinear residual map equipped with a convex outer loss. Benefiting from this structure, a structure-exploiting numerical method is developed by linearizing only the nonlinear residual map while preserving the convex outer loss. Thus, each subproblem is transformed into a structured convex form that can be solved reliably. The resulting generalized Gauss-Newton Hessian approximation is positive semidefinite and depends only on first-order derivatives, thereby supporting fast online computation. The proposed method is evaluated on a vehicle cruising auto-optimization problem and compared with existing methods. Simulation and hardware-in-the-loop experimental results show that the proposed method improves control performance and achieves a speedup of approximately one order of magnitude, with a microsecond-level maximum computation time of only 83 μs on a typical vehicle embedded CPU.
AERR-Nav: Adaptive Exploration-Recovery-Reminiscing Strategy for Zero-Shot Object Navigation
Mar 18, 2026Zero-Shot Object Navigation (ZSON) in unknown multi-floor environments presents a significant challenge. Recent methods, mostly based on semantic value greedy waypoint selection, spatial topology-enhanced memory, and Multimodal Large Language Model (MLLM) as a decision-making framework, have led to improvements. However, these architectures struggle to balance exploration and exploitation for ZSON when encountering unseen environments, especially in multi-floor settings, such as robots getting stuck at narrow intersections, endlessly wandering, or failing to find stair entrances. To overcome these challenges, we propose AERR-Nav, a Zero-Shot Object Navigation framework that dynamically adjusts its state based on the robot's environment. Specifically, AERR-Nav has the following two key advantages: (1) An Adaptive Exploration-Recovery-Reminiscing Strategy, enables robots to dynamically transition between three states, facilitating specialized responses to diverse navigation scenarios. (2) An Adaptive Exploration State featuring Fast and Slow-Thinking modes helps robots better balance exploration, exploitation, and higher-level reasoning based on evolving environmental information. Extensive experiments on the HM3D and MP3D benchmarks demonstrate that our AERR-Nav achieves state-of-the-art performance among zero-shot methods. Comprehensive ablation studies further validate the efficacy of our proposed strategy and modules.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023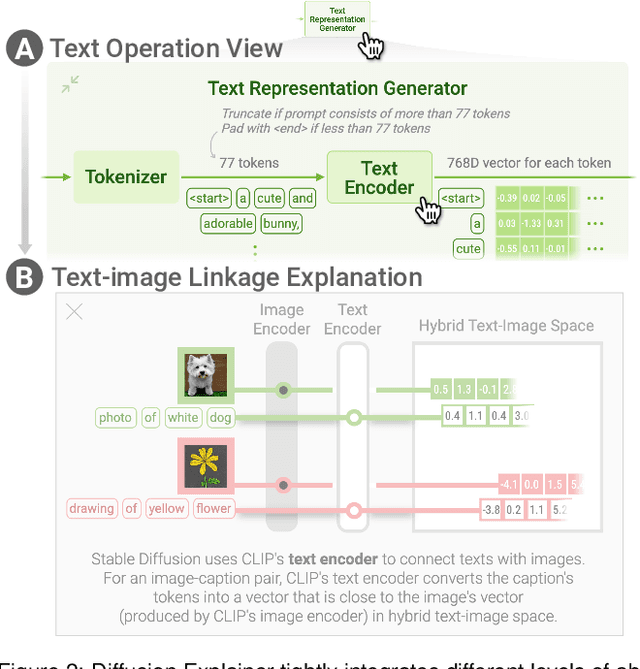
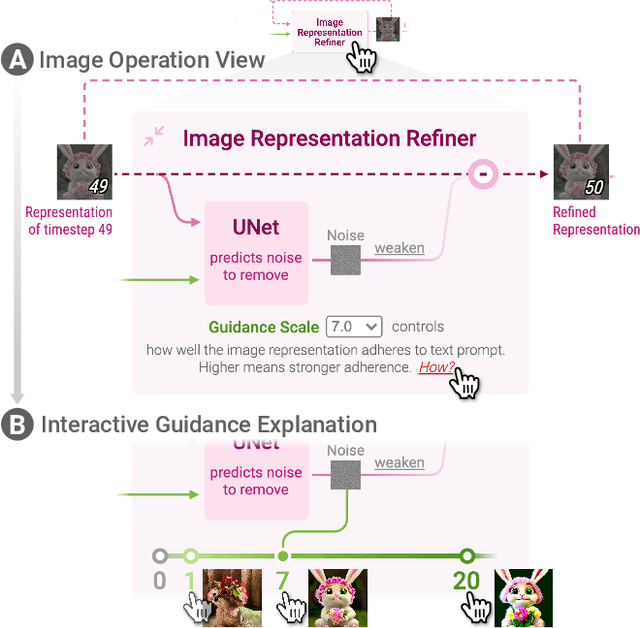
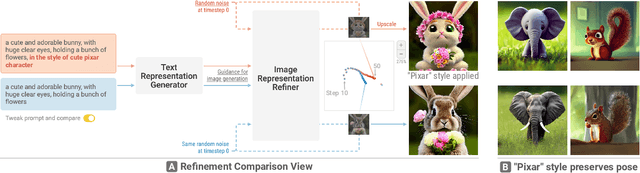
Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
Nov 15, 2022With recent advancements in diffusion models, users can generate high-quality images by writing text prompts in natural language. However, generating images with desired details requires proper prompts, and it is often unclear how a model reacts to different prompts and what the best prompts are. To help researchers tackle these critical challenges, we introduce DiffusionDB, the first large-scale text-to-image prompt dataset. DiffusionDB contains 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. We analyze prompts in the dataset and discuss key properties of these prompts. The unprecedented scale and diversity of this human-actuated dataset provide exciting research opportunities in understanding the interplay between prompts and generative models, detecting deepfakes, and designing human-AI interaction tools to help users more easily use these models. DiffusionDB is publicly available at: https://poloclub.github.io/diffusiondb.